TITLE: Finding, Sorting data, Multiple Type Returns, Overloading, Generics and Tuple Unpacking
EXTRA CONTENT: Making a fake Table(hashSets, overloading and generics)
INTRO - FOREWORDS
(What is the purpose of this video ?)
In this video i will show you how to find and sort data using loops,
as well as with find and sort procs.
Also Generics, more Overloading with and without Generics and Tuple Unpacking.
There is also a lot of cut content as an Extra,
which shows a lot more Generics and Overloading.
The code for this video and it's script/documentation styled with nimib,
as well as the cut content as an Extra, is in the links in the description as a form of written tutorial.
One can use the vertical bar/line | or , the or operator,
to specify that a proc can take OR return, multiple types of data.
or operator is mostly used in conditional statements e.g. if x or y, use | for types.
`or` is a remnant of the past
Example of multiple types for an argument:
proc stringOrInt(data: string | int) =
echo data
proc stringOrIntOr(data: stringorint) =
echo data
var str = "Hello"var num = 101
str.stringOrInt
num.stringOrInt
str.stringOrIntOr
num.stringOrIntOr
Hello
101
Hello
101
Example of multiple types for return:
proc multipleReturn(data: stringorint): stringorint = #This is now a `generic`! Multi return = genericresult = data
echo multipleReturn(101)
echo multipleReturn("Hello")
101
Hello
1.1. type or | type approach problem
If we were to change the body of the above proc,
to say data + data, we would get an error when the argument would be a string,
as you cannot join strings with the + operator(not unless you overload it,
but that is pointless, because & exists for this exact purpose).
Variable types must be known at compile-time, therefore you cannot use the vertical bar/line |,
or the or operator, to have a variable of multiple types.
The following does NOT compile:
var stringOrInt: string | int
I have seen this approach be used here and there, and i do not agree with it,
because of the above problem. You can solve by using some logic to check for the type beforehand.
But then, the code would be doing extra work, wasting performance.
SOLUTION 1: It would be much better to simply overload the same proc,
so that you have 2x procs or more, one for each of the types, to achieve the same functionality,
with none of the problems.
SOLUTION 2: Generics
1.2. Using static for compile-time multi return
One can also solve the above problem of the code appearing to be fine,
but then failing at compilation, or worse, sometime at runtime,
by using static dataType for the argument.
static enforces that the value will be known at compile-time,
therefore we do NOT need to check the types beforehand.
static type example:
proc test(x: staticbool): int | string = #Multi return = genericwhen x:
"Hello"else:
101echo test trueecho test false
If you need this to work at `runtime`, you should use the `union` module by `alaviss`:
- https://github.com/alaviss/union/
But i can't tell if it still works as nimble cannot find it. I don't want to waste time.
2. Finding and Sorting data
2.1. Finding the lowest number in a sequence
My version of how to find the lowest integer value in a sequence:
var listOfNumbers: seq[int]
listOfNumbers = @[1, 2, 50, 20, 100, 0, -5, 68, -100, 0, 100, 0]
var smallestNumber: int = int.high#So that it starts as the biggestfor number in listOfNumbers:
if number < smallestNumber:
smallestNumber = number
echo smallestNumber
-100
2.2. Finding the lowest number in a sequence using min/maxIndex
As you can see it's much simpler, but it is always valuable to learn how to do it yourself,
especially if you plan to make a similar proc.
2.3. Sorting a sequence of integers
My example of sorting a sequence of integers by their value descending(10, 9, 8...):
import std/sets, std/sequtils
var listOfNumbers: seq[int]
listOfNumbers = @[1, 2, 50, 20, 100, 0, -5, 68, -100, 0, 100, 0]
echo"Original listOfNumbers:"echo listOfNumbers; echo""var checkedNumbers: HashSet[int] #Max normal Set int size is int16var countedNumbers: seq[(int, seq[int])] #a Seq of (locations of number) - number of elements of locations = numb of of occurances#Finding all occurances of a number and their locationsfor index, number in listOfNumbers.pairs:
var tempSeq: seq[int]
var tempNum: intif number notin checkedNumbers:
for index2, number2 in listOfNumbers.pairs: #Double same loop, so that each number can check all the other numbers if index != index2: #Don't check the same position against the same positionif number == number2:
tempNum = number
checkedNumbers.incl number
tempSeq.add index #First location
tempSeq.add index2 #Second location#For single occurance numbers
tempNum = number
tempSeq.add index
#Multi occurance numbers
tempSeq = tempSeq.deduplicate
countedNumbers.add (tempNum, tempSeq)
echo"countedNumbers:"echo countedNumbers; echo""var sortedListOfNumbers: seq[int]
var smallestNumber: (int, seq[int]) = (int.high, @[])
var sNlocation: intwhile countedNumbers.len > 0:
smallestNumber = (int.high, @[]) #Reset - so that smallestNumber is always larger then the one in the list#Here we will remove once we break out with the smallestNumberfor index, tup in countedNumbers.pairs:
if tup[0] < smallestNumber[0]: #tup[0] -> number
smallestNumber = tup
sNlocation = index
countedNumbers.delete sNlocation
#Now we add number * locations to tempListOfNumbersfor location in smallestNumber[1]:
sortedListOfNumbers.add smallestNumber[0]
echo"sortedListOfNumbers"echo sortedListOfNumbers
sort proc modifies the existing variable, and uses the system.cmp for comparisons by default.
There is also the sorted proc, which returns a new copy instead of modifying the existing container.
sorted proc example:
echo listOfNumbers2.sorted() #You can't use `sort` with an echo like this
@[-100, -5, 0, 0, 0, 1, 2, 20, 50, 68, 100, 100]
You can also specify which comparison/cmp proc to use, like this:
echo listOfNumbers2.sorted(system.cmp[int])
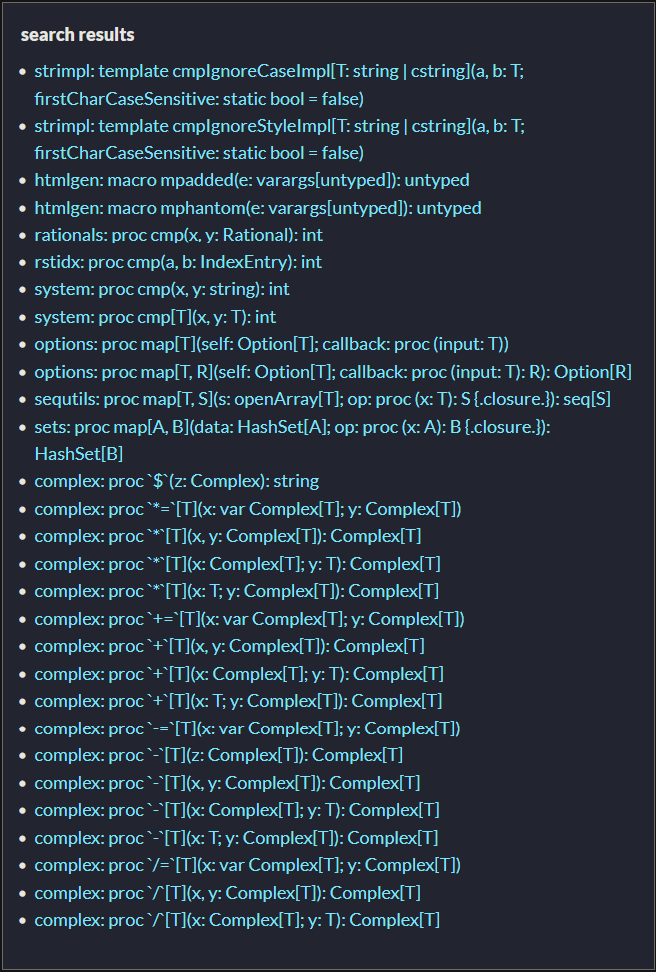
You can replace that cmp(compare) proc, with one of the following from the Nim's Standard Library's docs search results:
3. Generics
Generics in Nim, are used to parametrize procs, iterators or types with type parameters.
`[]` are used along with capital letters inside of them, separated by commas,
after a type's name, proc or iterator to tell the compiler that this will be a generic:
The above examples are incomplete, they will not work just yet.
Again, using `[]` with a capital letter inside will just "mark" the type, proc, iterator as a generic.
Now we require to use that T(can be any capital letter) in the arguments of the proc, iterator,
and on the fields of a type like so:
var genericObject = GenericObject[string](data: "A String")
var genericObject2 = GenericObject[int](data: 101)
echo genericObject, " of type ", genericObject.typeof
echo genericObject2, " of type ", genericObject2.typeof
(data: "A String") of type GenericObject[system.string]
(data: 101) of type GenericObject[system.int]
3.3. Generic Tuple Initialization
var genericTuple: GenericTuple[string, int] = ("Bob", 20)
var genericTuple2: GenericTuple[seq[float], bool] = (@[0.5, 1.1, 3.25], true)
echo genericTuple, " of type ", genericTuple.typeof
echo genericTuple2, " of type ", genericTuple2.typeof
(name: "Bob", age: 20) of type GenericTuple[system.string, system.int]
(name: @[0.5, 1.1, 3.25], age: true) of type GenericTuple[seq[float], system.bool]
Calling generic procs and iterators is exactly the same as non generic versions,
unlike structures like objects and tuples(shown above).
4. More Overloading
NOTE:hashSets, more on hash Tables and Hashing had the start of more overloading,
since the Nim for Beginners #22 Procedure Overloading(4 min long).
To demonstrate and teach you more about overloading, we are going to overload the find proc.
The find proc from the strutils module(string utilities)(also in some other modules),
is very useful for finding substrings(a part of a string) in a string.
In fact, we have already used it in both the Sets and the hashSets videos,
in order to find and remove specified separators from a string.
This time though, we are going to use the system.find version,
which does not deal with strings but with an element of some type.
4.1. Using find with a sequence of numbers
var mySequence = @[0, 2, 10, -10, 50]
echo mySequence.find(-10)
3
Like with all find proc versions, you give it what you want it to find, and it returns the index of where it is.
If you were to reinsert the index back, you would get -10 in this case:
let location = mySequence.find(-10)
echo mySequence[location]
-10
4.2. Using find with a sequence of objects
Now let's find an object based on one of it's fields in a sequence:
let wompRat = seqOfSomeObject.find("Womp rat")
echo"index of Womp rat: ", wompRat, " reinsertion: ", seqOfSomeObject[wompRat]
4.3. Overloading find proc
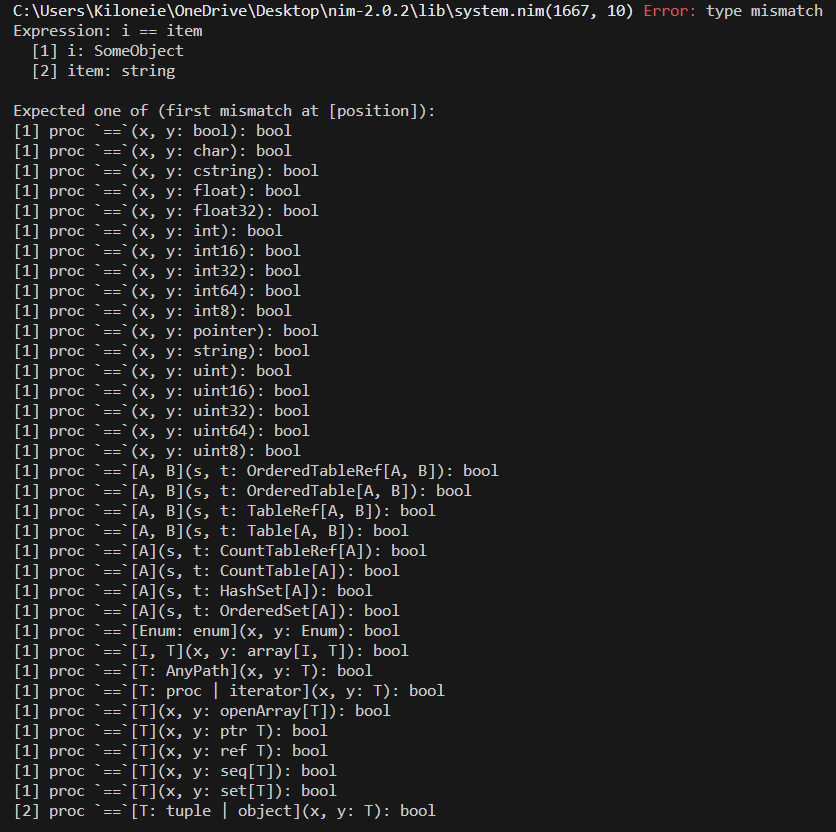
As you can see, find proc does not have a version/overload for our SomeObject,
and therefore does not compile.
So in order to make it work, we need to overload the find proc for our custom object:
First off, here is how the system.find proc is defined(a generic):
proc find*[T, S](a: T, item: S): int {.inline.}=
## Returns the first index of `item` in `a` or -1 if not found. This requires## appropriate `items` and `==` operations to work.result = 0for i in items(a):
if i == item: return
inc(result)
result = -1
Our overload, in order to find by the fields of our SomeObject:
#Can also be: proc find[T, S](a: T, item: S): int {.inline.} = #Specify for a single type, betterproc find[S](a: seq[SomeObject], item: S): int {.inline.} =
result = 0for index, element in a.pairs:
for f in element.fields: #Second unwrap to get the fields of `name: string` and `age: int`if $f == $item: return index #To string($) -> f(int) == item(string) -> ERROR#inc(result) #No longer needed as we are using the `pairs` iteratorresult = -1
let wompRat = seqOfSomeObject.find("Womp rat")
echo"Found name Womp rat at index: ", wompRat
echo"Reinsertion result: ", seqOfSomeObject[wompRat]
Found name Womp rat at index: 1
Reinsertion result: (name: "Womp rat", age: 5)
And now for the age field:
let ageOfWompRat = seqOfSomeObject.find(5)
echo"Found age 5 at index: ", ageOfWompRat
echo"Reinsertion result: ", seqOfSomeObject[ageOfWompRat]
Found age 5 at index: 1
Reinsertion result: (name: "Womp rat", age: 5)
4.4. [] overload for ease of life
`[]` overload will allow us to replace:
seqOfSomeObject.find("Womp rat") to seqOfSomeObject["Womp rat"] to get the index.
The overload is mostly the same as the find overload.
Except that the item argument is now a string instead of a generic.
This is because, if the overloaded `[]` was given an integer,
it would still try to return us the element at the index of that integer.
And in this instance 5 is not in the index of the 2 fields(0, 1),
resulting in an error.
import std/strutils
proc `[]`(a: seq[SomeObject], item: string): int {.inline.} =
result = 0for index, element in a.pairs:
for f in element.fields: #Second unwrap to get the fields of `name: string` and `age: int`if parseInt($f) isint: #`Line 1` Try to parse - to see if we get an `int`if $f == $item: return index #To string($) -> f(int) == item(string) -> ERRORelif $f == $item: return index
#inc(result) #No longer needed as we are using the `pairs` iteratorresult = -1
let name = seqOfSomeObject["Womp rat"]
echo"name's index: ", name
echo"Reinsertion result: ", seqOfSomeObject[name]
I don't think i have ever shown this before, but yes, you can access any field of a tuple,
without knowing the name of the field, especially useful for anonymous tuples like here(fields without names).
I do recommend though, that you do use the names of the fields over the index when the names are present.
(You do have to define a `tuple` type and declare/init a variable with that tuple type,
in order to be able to use named fields)
When tuple unpacking tuples with numbers(literals) into var and let variables,
they get assigned their values without a temporaryTuple.
Since you can nest any container withing another container(array, seq, set, table, etc),
as well as data structures in a data structure(object, tuple),
you can also use nested tuples for tuple unpacking.
5.1. Tuple Unpacking Use Case
In Nim you can have multiple return types for a proc,
by using object variants and union types(int|string).
This can also be achieved by using tuples. But tuples,
don't just allow for multiple types to be returned,
they allow for multiple returns, which can then be easily unpacked,
into variables and containers.
Here is an example of a multiple return:
proc returnsNestedTuple(): (int, (int, int), int, int) = (4, (5, 7), 2, 3)
let (x, (_, y), _, z) = returnsNestedTuple()
echo x, " ", y, " ", z
4 7 3
Another very useful part of tuple unpacking is that, you don't need to return anything.
1, 2, all or none.
Outro - Afterwords
Okay, that's it for this video, thanks for watching like, share and subscribe,
aswell as click the bell icon if you liked it and want more,
you can also support me on Patreon.
If you had any problems with any part of the video,
let me know in the comment section,
the code of this video, script and documentation, are in the link in the description,
as a form of written tutorial.
Thanks to my past and current Patrons
Past Patrons
Goose_Egg: From April 4th 2021 to May 10th 2022
Davide Galilei(1x month)
Current Patrons
jaap groot (from October 2023)
Dimitri Lesnoff (from October 2023)
Compiler Information
Version used: E.G. 2.0.2
Compiler settings used: none, ORC is now the default memory management option(mm:orc)
#Do NOT use {} inside nbText: hlMdF""" """ fields, sometimes it will error, not always#When using - to make a line a list item, you cannot have ANY one of the lines be an empty line#Use spaces by a factor of 2x for indentation in levels# *text* italic# **text** for bold instead of <b></b># ***text*** italic bold#Link 1 - <a href = "link"></a>#Link 2 - [name](link)#Link 3 `name <link>`_ -> without a name works too#nbCodeSkip -> skips the output/echo calls from the file, everything else remains the same#nbCodeInBlock -> opens up a new scope like the "block" statement, useful for when you don't want to use different variable names etc#https://pietroppeter.github.io/nimib/allblocks.html#nbShow is super useful!#https://nim-lang.org/docs/manual.html#lexical-analysis-raw-string-literals raw strings r""import nimib, std/strutils #You can use nimib's custom styling or HTML & CSS
nbInit()
nb.darkMode()
#nbShow() #This will auto open this file in the browser, but it does not check if it is already open#so it keeps bloody opening one after another, i just want a way to update changes quickly# customize source highlighting:
nb.context["highlight"] = """
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.5.0/styles/default.min.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/highlight.js/10.5.0/highlight.min.js"></script>
<script>hljs.initHighlightingOnLoad();</script>"""# a custom text block that shows markdown sourcetemplate nbTextWithSource*(body: untyped) =
newNbBlock("nbTextWithSource", false, nb, nb.blk, body):
nb.blk.output = body
nb.blk.context["code"] = body
nb.renderPlans["nbTextWithSource"] = @["mdOutputToHtml"]
nb.partials["nbTextWithSource"] = """{{&outputToHtml}}
<pre><code class=\"language-markdown\">{{code}}</code></pre>"""#Overriding nimib's nbCode -> with a version that has horizontal scroll for overflowing outputimport nimib / [capture]
template nbCode(body: untyped) =
newNbCodeBlock("nbCode", body): #Writes to stdout `lineNumb typeOfNBblock: a bit of first line
captureStdout(nb.blk.output):
body
nb.partials["nbCode"] = """
{{>nbCodeSource}}
<pre><code class=\"language-markdown\" style = "color:white;background-color: rgba(255, 255, 255, 0);font-size: 12px;">{{>nbCodeOutput}}</code></pre>
"""
nb.renderPlans["nbCode"] = @["highlightCode"] # default partial automatically escapes output (code is escaped when highlighting)# how to add a ToCvar
nbToc: NbBlocktemplate addToc =
newNbBlock("nbText", false, nb, nbToc, ""):
nbToc.output = "## Table of Contents:\n\n"var index = (section: 0, subsection: 0)
template nbSection(name:string) =
index.section.inc
index.subsection = 0#Reset on a new nbSectionlet anchorName = name.toLower.replace(" ", "-")
nbText "<a name = \"" & anchorName & "\"></a>\n# " & $index.section & ". " & name & "\n\n---"# see below, but any number works for a numbered list
nbToc.output.add "- " & $index.section & r"\. " & "<a href=\"#" & anchorName & "\">" & name & "</a>\n"#\ is HTML code for "\", you can also "\\" or r"\"#If you get an error from the above line, addToc must be ran before any nbSection template nbSubSection(name:string) =
index.subsection.inc
let anchorName = name.toLower.replace(" ", "-")
nbText "<a name = \"" & anchorName & "\"></a>\n## " & " " & $index.section & "." & $index.subsection & ". " & name & "\n\n---"# is inline HTML for a single white space(nothing in markdown)# see below, but any number works for a numbered list
nbToc.output.add " - " & $index.section & r"\." & $index.subsection & r"\. " & "<a href=\"#" & anchorName & "\">" & name & "</a>\n"#If you get an error from the above line, addToc must be ran before any nbSection template nbUoSection(name: string) =
nbText "\n# " & name & "\n\n---"template nbUoSubSection(name: string) =
nbText "\n## " & name & "\n\n---"#Updating the same file is shown instantly once deployed via Github Page on PC(not always). #Mobile takes either a random amount of time, or NOT at all!template addButtonBackToTop() =
nbRawHtml: hlHtml"""
<meta name = "viewport" content = "width = device-width, initial-scale = 1">
<style>
body {} <!-- This is a comment, this needs to be here body {} -->
#toTop {
display: none;
position: fixed;
bottom: 20px;
right: 30px;
z-index: 99;
font-size: 18px;
border: none;
outline: none;
background-color: #1A222D;
color: white;
cursor: pointer;
padding: 15px;
border-radius: 4px;
}
#toTop:hover {background-color: #555;}
#toTopMobile {
display: none;
position: fixed;
bottom: -5px;
right: -5px;
z-index: 99;
font-size: 18px;
border: none;
outline: none;
background-color: #1A222D;
opacity: .2;
color: white;
cursor: pointer;
padding: 15px;
border-radius: 4px;
}
#toTopMobile:hover {background-color: #555;}
</style>
<body>
<button onclick = "topFunction()" id = "toTop" title = "Go to top">Top</button>
<button onclick = "topFunction()" id = "toTopMobile" title = "Go to top">Top</button>
<script>
// Get the button
let myButton = document.getElementById("toTop");
let myButtonMobile = document.getElementById("toTopMobile");
var currentButton = myButton
var hasTouchScreen = false;
//var contentBody = document.getElementsByTagName("body"); //gives a query object
//myButton.style.color = "red"; //This works
//myButton.textContent = contentBody; //This also works .innerHTML, .innerText
//document.body.scrollTop > 20 || document.documentElement.scrollTop > 20
//Above could be used to position the button relativly ?
// Detecting if the device is a mobile device
if ("maxTouchPoints" in navigator)
{
hasTouchScreen = navigator.maxTouchPoints > 0;
}
else if ("msMaxTouchPoints" in navigator)
{
hasTouchScreen = navigator.msMaxTouchPoints > 0;
}
else
{
var mQ = window.matchMedia && matchMedia("(pointer:coarse)");
if (mQ && mQ.media === "(pointer:coarse)")
{
hasTouchScreen = !!mQ.matches;
}
else if ('orientation' in window)
{
hasTouchScreen = true; // deprecated, but good fallback
}
else
{
// Only as a last resort, fall back to user agent sniffing
var UA = navigator.userAgent;
hasTouchScreen = (
/\b(BlackBerry|webOS|iPhone|IEMobile)\b/i.test(UA) ||
/\b(Android|Windows Phone|iPad|iPod)\b/i.test(UA)
);
}
}
if (hasTouchScreen)
currentButton = myButtonMobile
// When the user scrolls down 20px from the top of the document, show the button
window.onscroll = function()
{
scrollFunction()
};
function scrollFunction()
{
if (document.body.scrollTop > 20 || document.documentElement.scrollTop > 20) {
currentButton.style.display = "block";
} else {currentButton.style.display = "none";}
}
// When the user clicks on the button, scroll to the top of the document
function topFunction() {
document.body.scrollTop = 0;
document.documentElement.scrollTop = 0;
}
</script>
"""#TABLE OF CONTENTS - MUST BE RUN BEFORE ANY nbSection !!!
addToc()
addButtonBackToTop()
#Use Live Preview Extension and set the Auto Refresh Preview set to "On changes to Saved Files"#And Server Keep Alive After Embedded Preview Close set to 0, #so that we no longer need the preview embedded window, we now have it in the browser!#Live SERVER Extension no longer works, even with the .html file kept open################START OF FILE#################Adding hlMd or hlMdf enables nimiboost's markdown highlight mode
nbText: hlMdF"""
## INTRO - GREETING
- TITLE: Finding, Sorting data, Multiple Type Returns, Overloading, Generics and Tuple Unpacking
- EXTRA CONTENT: Making a fake Table(hashSets, overloading and generics)
## INTRO - FOREWORDS
<b>(What is the purpose of this video ?)</b>
- In this video i will show you how to find and sort data using loops,
as well as with `find` and `sort` procs.
Also Generics, more Overloading with and without Generics and Tuple Unpacking.
There is also a lot of cut content as an Extra,
which shows a lot more Generics and Overloading.
The code for this video and it's script/documentation styled with nimib,
as well as the cut content as an Extra, is in the links in the description as a form of written tutorial.
- [Extra Content](https://kiloneie.github.io/Extra%20Content/extraMakingFakeTable.html "Extra Content")
"""
nbSection "Multiple Type Arguments and Returns"
nbText """
One can use the vertical bar/line `|` or , the `or` operator,
to specify that a proc can take OR return, multiple types of data.
`or` operator is mostly used in conditional statements e.g. `if x or y`, use `|` for types.
<h6>`or` is a remnant of the past</h6>
**Example of multiple types for an argument:**
"""
nbCodeInBlock:
proc stringOrInt(data: string | int) =
echo data
proc stringOrIntOr(data: stringorint) =
echo data
var str = "Hello"var num = 101
str.stringOrInt
num.stringOrInt
str.stringOrIntOr
num.stringOrIntOr
nbText: """
**Example of multiple types for return:**
"""
nbCode:
proc multipleReturn(data: stringorint): stringorint = #This is now a `generic`! Multi return = genericresult = data
echo multipleReturn(101)
echo multipleReturn("Hello")
nbSubSection "`type or | type` approach problem"
nbText: """
If we were to change the body of the above proc,
to say `data + data`, we would get an error when the argument would be a `string`,
as you cannot join strings with the `+` operator(not unless you overload it,
but that is pointless, because `&` exists for this exact purpose).
Variable types must be known at compile-time, therefore you cannot use the vertical bar/line `|`,
or the `or` operator, to have a variable of multiple types.
**The following does NOT compile:**
"""
nbCodeSkip:
var stringOrInt: string | int
nbText: """
I have seen this approach be used here and there, and i do not agree with it,
because of the above problem. You can solve by using some logic to check for the type beforehand.
But then, the code would be doing extra work, wasting performance.
**SOLUTION 1:** It would be much better to simply `overload` the same `proc`,
so that you have 2x procs or more, one for each of the types, to achieve the same functionality,
with none of the problems.
**SOLUTION 2:** Generics
"""
nbSubSection: "Using `static` for compile-time multi return"
nbText: """
One can also solve the above problem of the code appearing to be fine,
but then failing at compilation, or worse, sometime at runtime,
by using `static` dataType for the argument.
`static` enforces that the value will be known at compile-time,
therefore we do NOT need to check the types beforehand.
**`static` type example:**
"""
nbCode:
proc test(x: staticbool): int | string = #Multi return = genericwhen x:
"Hello"else:
101echo test trueecho test false
nbText: """
The following `runtime` version does NOT compile:
"""
nbCodeSkip:
proc testR(x: bool): int | string = #Multi return = genericwhen x:
"Hello"else:
101echo testR trueecho testR false
nbText: """
<h6>If you need this to work at `runtime`, you should use the `union` module by `alaviss`:
- https://github.com/alaviss/union/
But i can't tell if it still works as nimble cannot find it. I don't want to waste time.</h6>
"""
nbSection "Finding and Sorting data"
nbSubSection "Finding the lowest number in a sequence"
nbText: """
My version of how to find the lowest integer value in a sequence:
"""
nbCodeInBlock:
var listOfNumbers: seq[int]
listOfNumbers = @[1, 2, 50, 20, 100, 0, -5, 68, -100, 0, 100, 0]
var smallestNumber: int = int.high#So that it starts as the biggestfor number in listOfNumbers:
if number < smallestNumber:
smallestNumber = number
echo smallestNumber
nbSubSection "Finding the lowest number in a sequence using `min/maxIndex`"
nbText: """
`sequtils`(sequence utilities) module's `min/maxIndex` proc:
"""
nbCode:
import std/sequtils
var numbers: seq[int]
numbers = @[1, 2, 50, 20, 100, 0, -5, 68, -100, 0, 100, 0]
echo numbers[numbers.minIndex]
echo numbers[numbers.maxIndex]
nbText: """
As you can see it's much simpler, but it is always valuable to learn how to do it yourself,
especially if you plan to make a similar proc.
"""
nbSubSection "Sorting a sequence of integers"
nbText """
My example of sorting a sequence of integers by their value descending(10, 9, 8...):
"""
nbCode:
import std/sets, std/sequtils
var listOfNumbers: seq[int]
listOfNumbers = @[1, 2, 50, 20, 100, 0, -5, 68, -100, 0, 100, 0]
echo"Original listOfNumbers:"echo listOfNumbers; echo""var checkedNumbers: HashSet[int] #Max normal Set int size is int16var countedNumbers: seq[(int, seq[int])] #a Seq of (locations of number) - number of elements of locations = numb of of occurances#Finding all occurances of a number and their locationsfor index, number in listOfNumbers.pairs:
var tempSeq: seq[int]
var tempNum: intif number notin checkedNumbers:
for index2, number2 in listOfNumbers.pairs: #Double same loop, so that each number can check all the other numbers if index != index2: #Don't check the same position against the same positionif number == number2:
tempNum = number
checkedNumbers.incl number
tempSeq.add index #First location
tempSeq.add index2 #Second location#For single occurance numbers
tempNum = number
tempSeq.add index
#Multi occurance numbers
tempSeq = tempSeq.deduplicate
countedNumbers.add (tempNum, tempSeq)
echo"countedNumbers:"echo countedNumbers; echo""var sortedListOfNumbers: seq[int]
var smallestNumber: (int, seq[int]) = (int.high, @[])
var sNlocation: intwhile countedNumbers.len > 0:
smallestNumber = (int.high, @[]) #Reset - so that smallestNumber is always larger then the one in the list#Here we will remove once we break out with the smallestNumberfor index, tup in countedNumbers.pairs:
if tup[0] < smallestNumber[0]: #tup[0] -> number
smallestNumber = tup
sNlocation = index
countedNumbers.delete sNlocation
#Now we add number * locations to tempListOfNumbersfor location in smallestNumber[1]:
sortedListOfNumbers.add smallestNumber[0]
echo"sortedListOfNumbers"echo sortedListOfNumbers
nbText: """
As you can see, for just sorting numbers in a sequence, it takes a lot of code to do so.
"""
nbSubSection "Sorting a sequence of integers using `sort`"
nbText: """
**`sort` is Nim's default sorting algorithm - func(there is also a `proc` verison)**
"""
nbCode:
import std/algorithm
var listOfNumbers2: seq[int]
listOfNumbers2 = @[1, 2, 50, 20, 100, 0, -5, 68, -100, 0, 100, 0]
echo"Original listOfNumbers2:"echo listOfNumbers2; echo""var sortedListOfNumbers2 = listOfNumbers2
sortedListOfNumbers2.sort() #Default is lowest to highest - Ascendingecho"sortedListOfNumbers2"echo sortedListOfNumbers2
nbText: """
As you can see, it saves you a LOT of time(it took me quite a bit to write my own above).
**Descending `sort` example:**
"""
nbCode:
sortedListOfNumbers2.sort(order = SortOrder.Descending)
echo"sortedListOfNumbers2 in Descending order:"echo sortedListOfNumbers2
nbText: """
`sort` proc modifies the existing variable, and uses the `system.cmp` for comparisons by default.
There is also the `sorted` proc, which returns a new copy instead of modifying the existing container.
**`sorted` proc example:**
"""
nbCode:
echo listOfNumbers2.sorted() #You can't use `sort` with an echo like this
nbText: """
You can also specify which comparison/`cmp` proc to use, like this:
"""
nbCodeSkip:
echo listOfNumbers2.sorted(system.cmp[int])
nbText: """
You can replace that `cmp`(compare) proc, with one of the following from the Nim's Standard Library's docs search results:
"""
nbRawHtml: """<img src = "images/cmpSearchResults.png" alt = "`cmp` search results">"""
nbSection "Generics"
nbText: """
Generics in Nim, are used to parametrize procs, iterators or types with type parameters.
\`[]\` are used along with capital letters inside of them, separated by commas,
after a type's name, proc or iterator to tell the compiler that this will be a `generic`:
"""
nbCodeSkip:
typeGenericObject[T] = object
ndata: stringproc genericProc[T]() =
discarditerator genericIterator[T]() =
discard
nbText """
The above examples are incomplete, they will not work just yet.
Again, using \`[]\` with a capital letter inside will just "mark" the `type, proc, iterator` as a generic.
Now we require to use that `T`(can be any capital letter) in the arguments of the `proc`, `iterator`,
and on the fields of a `type` like so:
"""
nbSubSection "Generic Definitions"
nbCode:
typeGenericObject[T] = object
data: TtypeGenericTuple[A, B] = tuple
name: A
age: Bproc genericProc[T](anyType: T) =
discarditerator genericIterator[T](anyType: T): T =
discard
nbText: """
**And also for generic containers proc definition example**
"""
nbCode:
proc genericContainerProc[T](anyTypeContainer: seq[T]) =
discard
nbText: """
Now let's see how to use this `generic object`
"""
nbSubSection "Generic Object Initialization"
nbCode:
var genericObject = GenericObject[string](data: "A String")
var genericObject2 = GenericObject[int](data: 101)
echo genericObject, " of type ", genericObject.typeof
echo genericObject2, " of type ", genericObject2.typeof
nbSubSection "Generic Tuple Initialization"
nbCode:
var genericTuple: GenericTuple[string, int] = ("Bob", 20)
var genericTuple2: GenericTuple[seq[float], bool] = (@[0.5, 1.1, 3.25], true)
echo genericTuple, " of type ", genericTuple.typeof
echo genericTuple2, " of type ", genericTuple2.typeof
nbText: """
Calling generic procs and iterators is exactly the same as non generic versions,
unlike structures like `objects` and `tuples`(shown above).
"""
nbSection "More Overloading"
nbText: """
**NOTE:** `hashSets, more on hash Tables and Hashing` had the start of `more` overloading,
since the Nim for Beginners #22 Procedure Overloading(4 min long).
To demonstrate and teach you more about overloading, we are going to overload the `find` proc.
The `find` proc from the `strutils` module(string utilities)(also in some other modules),
is very useful for finding substrings(a part of a string) in a string.
In fact, we have already used it in both the Sets and the hashSets videos,
in order to `find` and remove specified separators from a string.
This time though, we are going to use the `system.find` version,
which does not deal with `strings` but with an element of some type.
"""
nbSubSection "Using `find` with a sequence of numbers"
nbCode:
var mySequence = @[0, 2, 10, -10, 50]
echo mySequence.find(-10)
nbText: """
Like with all `find` proc versions, you give it what you want it to find, and it returns the `index` of where it is.
**If you were to reinsert the index back, you would get -10 in this case:**
"""
nbCode:
let location = mySequence.find(-10)
echo mySequence[location]
nbSubSection "Using `find` with a sequence of objects"
nbText: """
**Now let's find an object based on one of it's fields in a sequence:**
"""
nbCode:
typeSomeObject = object
name: string
age: intvar seqOfSomeObject: seq[SomeObject]
seqOfSomeObject.add SomeObject(name: "Wombat", age: 3)
seqOfSomeObject.add SomeObject(name: "Womp rat", age: 5)
nbCodeSkip:
let wompRat = seqOfSomeObject.find("Womp rat")
echo"index of Womp rat: ", wompRat, " reinsertion: ", seqOfSomeObject[wompRat]
nbRawHtml: """<img src = "images/findProcError.png" alt = "`find` proc error">"""
nbSubSection "Overloading `find` proc"
nbText: """
As you can see, `find` proc does not have a version/overload for our `SomeObject`,
and therefore does not compile.
**So in order to make it work, we need to overload the `find` proc for our custom object:**
First off, here is how the `system.find` proc is defined(a generic):
"""
nbCodeSkip:
proc find*[T, S](a: T, item: S): int {.inline.}=
## Returns the first index of `item` in `a` or -1 if not found. This requires## appropriate `items` and `==` operations to work.result = 0for i in items(a):
if i == item: return
inc(result)
result = -1
nbText """
Our overload, in order to `find` by the fields of our `SomeObject`:
"""
nbCode:
#Can also be: proc find[T, S](a: T, item: S): int {.inline.} = #Specify for a single type, betterproc find[S](a: seq[SomeObject], item: S): int {.inline.} =
result = 0for index, element in a.pairs:
for f in element.fields: #Second unwrap to get the fields of `name: string` and `age: int`if $f == $item: return index #To string($) -> f(int) == item(string) -> ERROR#inc(result) #No longer needed as we are using the `pairs` iteratorresult = -1
nbCode:
let wompRat = seqOfSomeObject.find("Womp rat")
echo"Found name Womp rat at index: ", wompRat
echo"Reinsertion result: ", seqOfSomeObject[wompRat]
nbText: """
And now for the `age` field:
"""
nbCode:
let ageOfWompRat = seqOfSomeObject.find(5)
echo"Found age 5 at index: ", ageOfWompRat
echo"Reinsertion result: ", seqOfSomeObject[ageOfWompRat]
nbSubSection "`[]` overload for ease of life"
nbText: """
\`[]\` overload will allow us to replace:
`seqOfSomeObject.find("Womp rat")` to `seqOfSomeObject["Womp rat"]` to get the index.
The overload is mostly the same as the `find` overload.
**Except that the `item` argument is now a `string` instead of a generic.**
This is because, if the overloaded \`[]\` was given an `integer`,
it would still try to return us the element at the index of that `integer`.
And in this instance `5` is not in the index of the 2 fields(0, 1),
resulting in an error.
"""
nbCodeSkip:
import std/strutils
nbCode:
proc `[]`(a: seq[SomeObject], item: string): int {.inline.} =
result = 0for index, element in a.pairs:
for f in element.fields: #Second unwrap to get the fields of `name: string` and `age: int`if parseInt($f) isint: #`Line 1` Try to parse - to see if we get an `int`if $f == $item: return index #To string($) -> f(int) == item(string) -> ERRORelif $f == $item: return index
#inc(result) #No longer needed as we are using the `pairs` iteratorresult = -1
nbCode:
let name = seqOfSomeObject["Womp rat"]
echo"name's index: ", name
echo"Reinsertion result: ", seqOfSomeObject[name]
nbText: """
The following will NOT compile, and crash if the `item` argument is a generic.
"""
nbCodeSkip:
let age = seqOfSomeObject[5] #Index out of bounds - no crash yetecho"age's index: ", age
echo"Reinsertion result: ", seqOfSomeObject[age] #Crash here
nbText: """
What we can do is make that number `5` into a string `$5`.
"""
nbCode:
let age = seqOfSomeObject[$5]
echo"age's index: ", age
echo"Reinsertion result: ", seqOfSomeObject[age]
nbSection "Tuple Unpacking"
nbText """
In the past video of `Nim for Beginners #14 Tuples`, i have shown you Tuples.
<h5>(There is a lot of dealing with `tuples` in the Extra cut content)</h5>
Now it's time to explain and demonstrate `tuple unpacking`. Tuple unpacking is quite simple.
You can use them to give values(assignment) to multiple variables(`var`), constants(`const`) or immutable variable(`let`),
at once.
**Example 1:**
"""
nbCode:
let (v1, c1, l1) = ("var", "const", "let")
echo v1
echo c1
echo l1
nbText: """
**You may also ommit assignment of any of them:**
"""
nbCode:
let (v2, _, l2) = ("var", "const", "let")
let (_, _, _) = ("var", "const", "let")
nbText: """
**All of this is treated as syntatic sugar for basically the following code(Example 1):**
"""
nbCode:
let
temporaryTuple = ("var", "const", "let")
v3 = temporaryTuple[0]
c3 = temporaryTuple[1]
l3 = temporaryTuple[2]
nbText: """
I don't think i have ever shown this before, but yes, you can access any field of a `tuple`,
without knowing the name of the field, especially useful for `anonymous` tuples like here(fields without names).
I do recommend though, that you do use the `names` of the fields over the `index` when the `names` are present.
<h5>(You do have to define a `tuple` type and declare/init a variable with that tuple type,
in order to be able to use named fields)</h5>
When tuple unpacking tuples with numbers(literals) into `var` and `let` variables,
they get assigned their values without a `temporaryTuple`.
Since you can nest any container withing another container(array, seq, set, table, etc),
as well as data structures in a data structure(object, tuple),
you can also use nested tuples for tuple unpacking.
"""
nbSubSection "Tuple Unpacking Use Case"
nbText: """
In Nim you can have multiple return types for a `proc`,
by using `object variants` and `union types`(int|string).
This can also be achieved by using `tuples`. But `tuples`,
don't just allow for multiple types to be returned,
they allow for multiple returns, which can then be easily `unpacked`,
into variables and containers.
**Here is an example of a multiple return:**
"""
nbCode:
proc returnsNestedTuple(): (int, (int, int), int, int) = (4, (5, 7), 2, 3)
let (x, (_, y), _, z) = returnsNestedTuple()
echo x, " ", y, " ", z
nbText: """
Another very useful part of `tuple unpacking` is that, you don't need to return anything.
1, 2, all or none.
"""
nbUoSection "Outro - Afterwords"
nbText: """
Okay, that's it for this video, thanks for watching like, share and subscribe,
aswell as click the bell icon if you liked it and want more,
you can also support me on Patreon.
If you had any problems with any part of the video,
let me know in the comment section,
the code of this video, script and documentation, are in the link in the description,
as a form of written tutorial.
"""
nbUoSection "Thanks to my past and current Patrons"
nbUoSubSection "Past Patrons"
nbText: """
- Goose_Egg: From April 4th 2021 to May 10th 2022
- Davide Galilei(1x month)
"""
nbUoSubSection "Current Patrons"
nbText: """
- jaap groot (from October 2023)
- Dimitri Lesnoff (from October 2023)
"""
nbUoSubSection "Compiler Information"
nbText: """
- Version used: E.G. 2.0.2
- Compiler settings used: none, ORC is now the default memory management option(mm:orc)
"""
nbUoSubSection "My and General Links"
nbText: """
- [Extra Content](https://kiloneie.github.io/Extra%20Content/extraMakingFakeTable.html "Extra Content")
- [Patreon](https://www.patreon.com/Kiloneie?fan_landing=true "Patreon")
- [Visual Studio Code Shortcuts](https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf "Visual Studio Code Shortcuts")
"""
nbUoSubSection "Links to this video's subject"
nbText: """
- [min/maxIndex procs](https://nim-lang.org/docs/sequtils.html#minIndex%2CopenArray%5BT%5D "min/maxIndex procs")
- [for `sort` func and `sorted` proc](https://nim-lang.org/docs/algorithm.html#sort%2CopenArray%5BT%5D%2Cproc%28T%2CT%29 "for `sort` func and `sorted` proc")
- [parseInt](https://nim-lang.org/docs/strutils.html#parseInt%2Cstring "parseInt")
"""
nbSave()